1. 机器学习引入
试想这样一个场景,傍晚小街路面上沁出微雨后的湿润,和煦的细风吹来,抬头看看天边的晚霞。心里想着明天又是一个好天气。
走到水果摊旁,挑了个色泽青绿、敲起来声音浊响的青绿西瓜,一边期待着西瓜皮薄肉厚瓤甜的爽落感。
回想刚刚我们的场景,我们会发现这里涉及很多基于经验做出的预判。
- 为什么看到微湿路面、感到和风、天边晚霞就认为明天是好天呢? 答:这是因为在我们的生活经验中已经遇见过很多类似的情况,前一天观察到上述特征后,第二天天气通常会很好。
- 为什么色泽青绿、敲声浊响就能判断出是正熟的好西瓜呢? 答:这是因为我们吃过、看过很多的西瓜,所以基于色泽、敲声这几个特征我们就可以做出相当好的判断。
简言之: 我们也可以把这些经验交给计算机, 由计算机给出预测.
2. 机器学习基本概念
机器学习专门研究计算机怎样模拟或实现人类的学习行为,使之不断改善自身性能。是一门能够发掘数据价值的算法和应用,我们生活在一个数据资源非常丰富的年代,通过机器学习中的自学习算法,可以将这些数据转换为知识。
借助于近些年发展起来的诸多强大的开源库,现在是进入机器学习领域的最佳时机。
机器学习模型 = 数据 + 机器学习算法
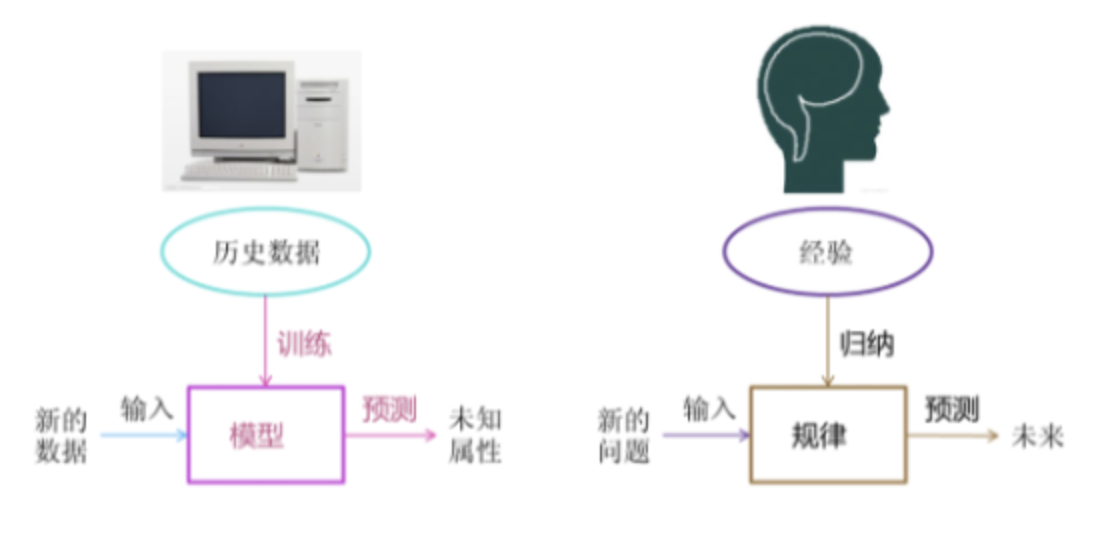
但是在没有机器学习之前,都是基于规则学习的方式
3. 基于规则的学习
在机器学习出来之前,我们进行预测,需要先有一个明确的可解释的规则,如下案例:
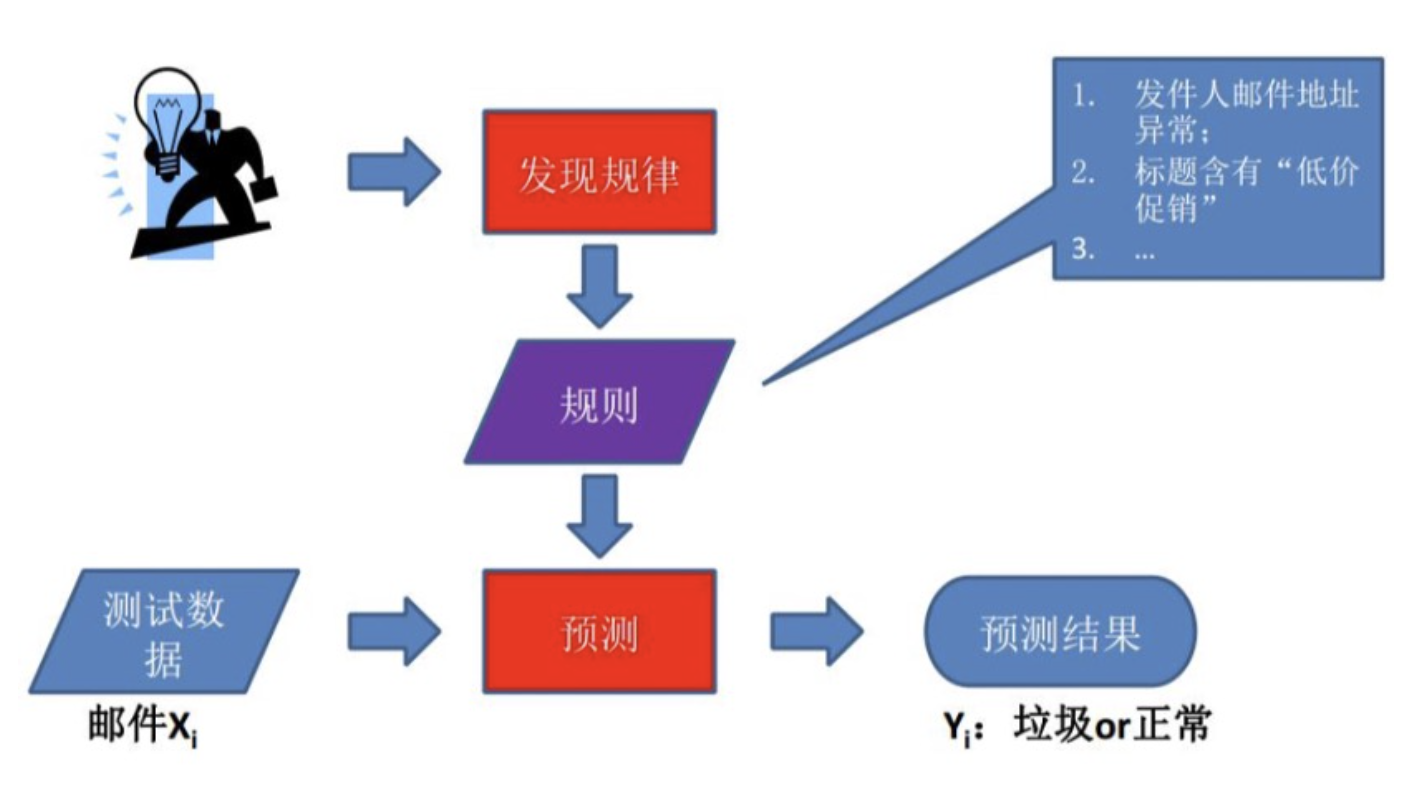
基于规则的分类器是使用一组 “if…else…” 规则来对样本进行分类的技术
但是有好多问题, 无法明确的写下规则,此时我们无法使用规则学习的方式来解决这一类问题,比如:
- 图像和语音识别
- 自然语言处理
举例:我们尝试通过基于规则的学习方式让计算机识别大象,下图中的大象千差万别, 有的是实物,有的是雕塑,有的是画,我们无法通过创建一套规则的方式让计算机准确识别下面每一头大象, 此时我们需要一种新的方法来解决这类问题。

4. 基于模型学习
基于模型的学习就是通过编写机器学习程序,让机器自己学习从历史数据中获得经验、训练模型:
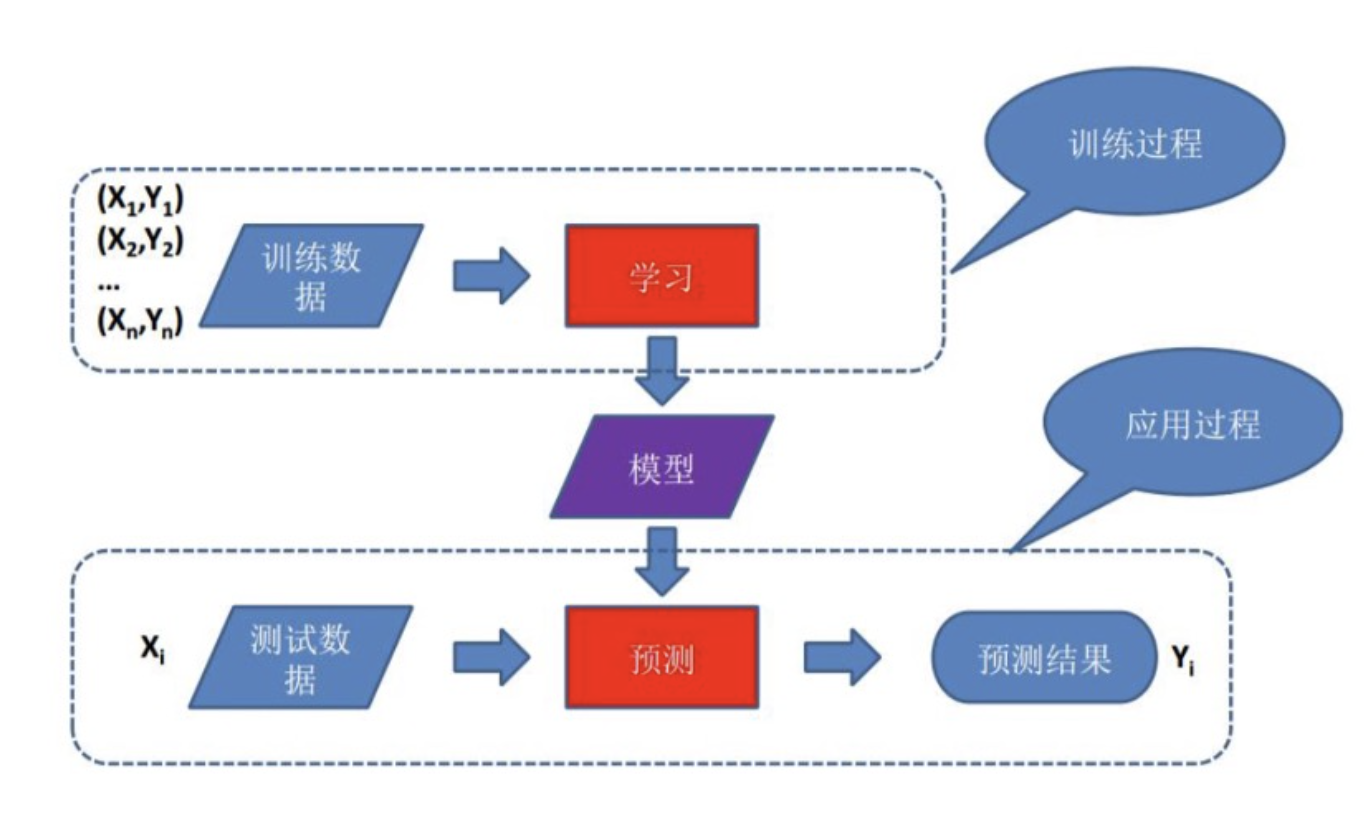
案例巩固
比如房价预测,数据如下图
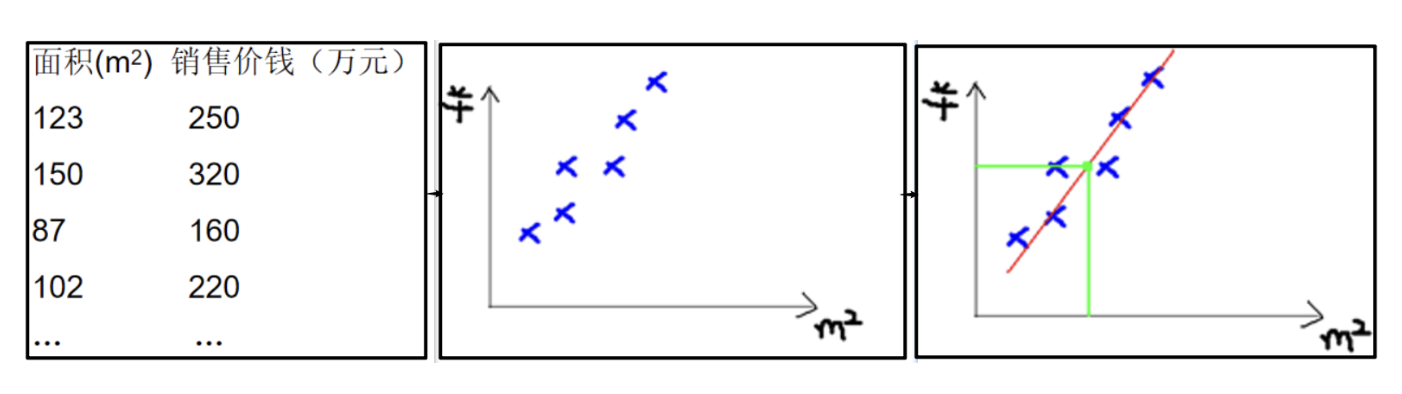
- 我们可以使用一条直线尽可能多的通过这些点,不通过的点尽量分布在直线的两侧,利用这条直线所表示的线性关系,我们就可以预测房价。
- 直线可以写成y=ax+b,若a,b已知,我们就能够预测房价。机器学习中a,b称为 参数 ,y=ax+b称为 模型 。通常a,b未知,是我们需要求解的量。
5. 机器学习数据集描述
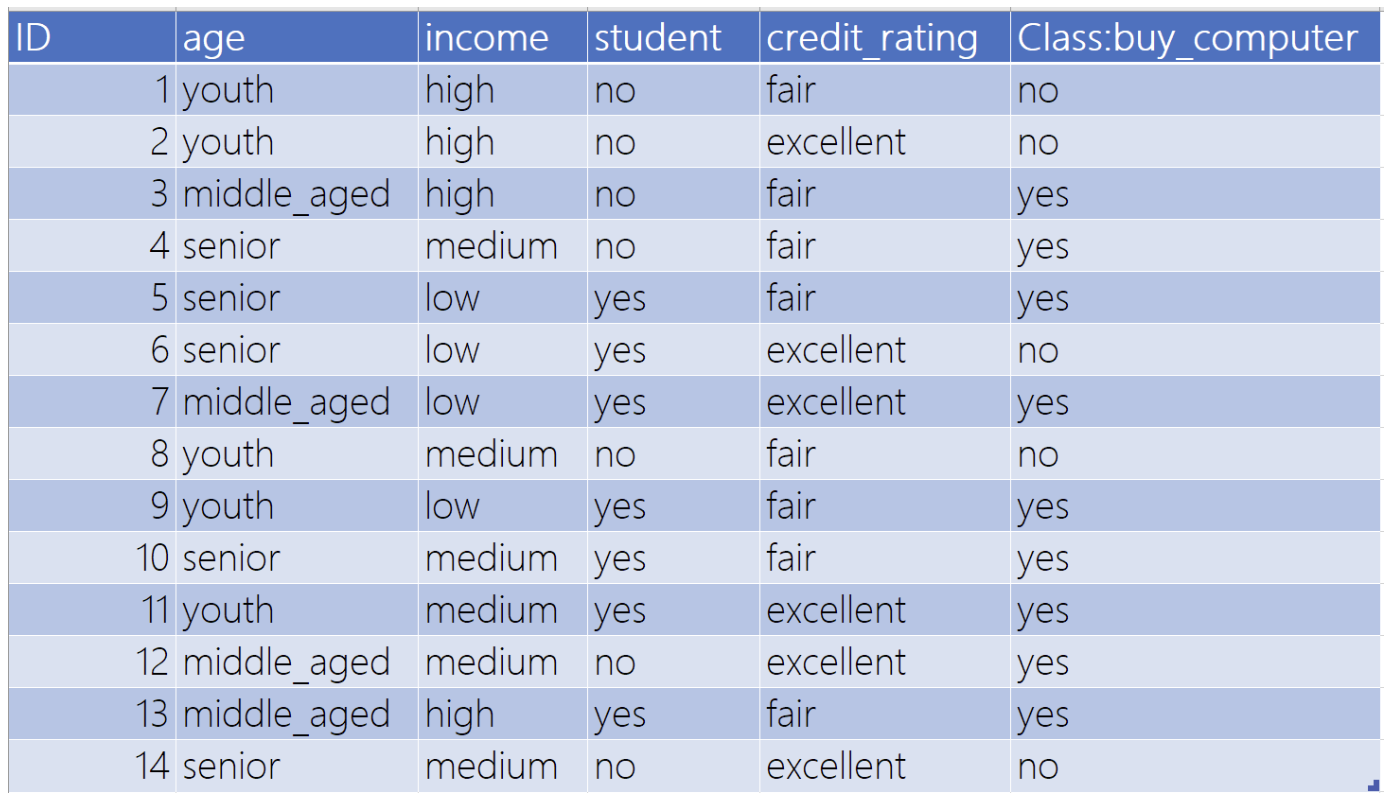
数据集如下:
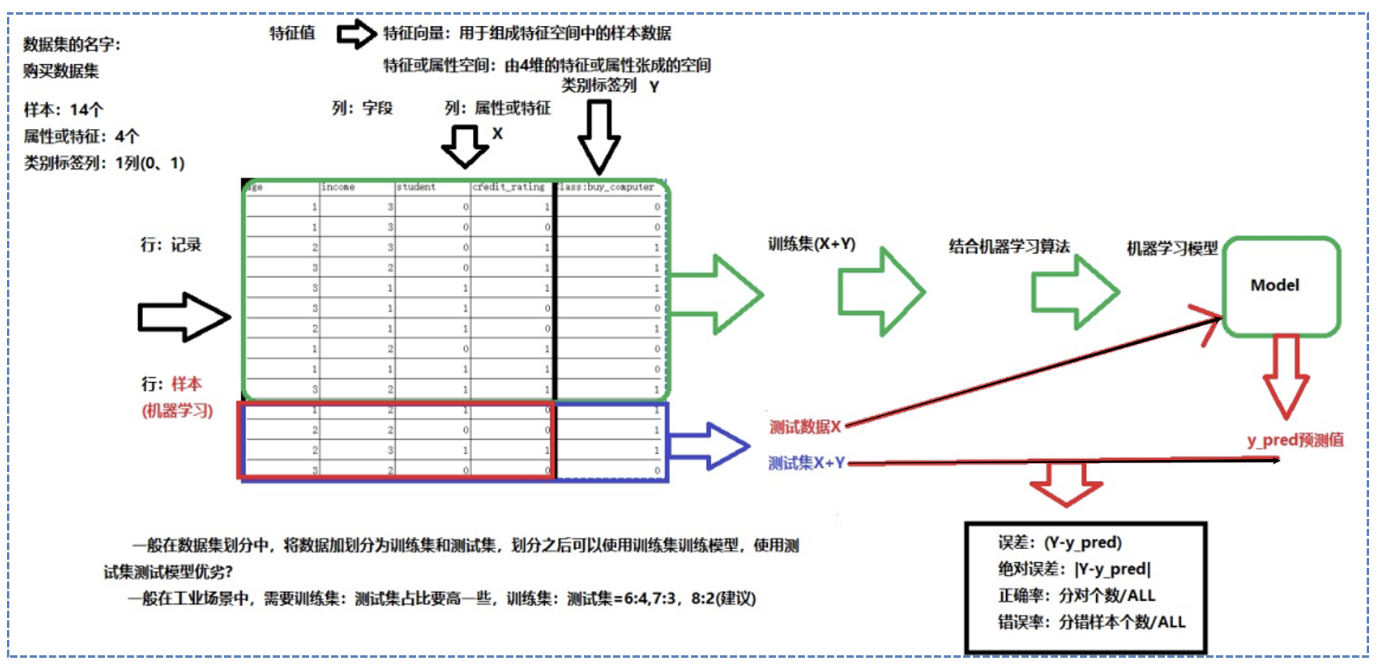
通过电商购买数据集了解机器学习数据集的构成:其中每一个用户都由age年龄、income收入、student是否为学生、credit_rating信用级别和buy_computer是否购买电脑组成。
数据集描述如下
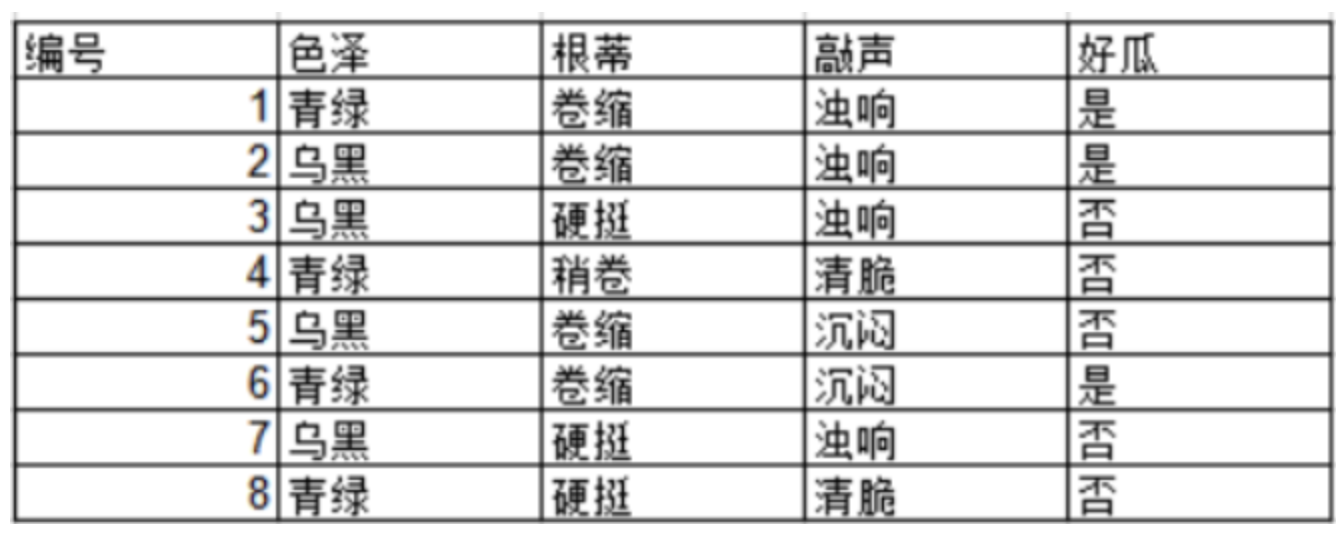
案例实操:
西瓜数据集,可以通过西瓜的色泽、根蒂、敲声确定一个西瓜是好瓜或坏瓜,可以做详细分析:
鸢尾花数据集
鸢尾花Iris Dataset数据集是机器学习领域经典数据集,该数据集可以从加州大学欧文分校(UCI)的机器学习库中得到。鸢尾花数据集包含了150条鸢尾花信息,每50条取自三个鸢尾花中之一:Versicolour、Setosa和Virginica

每个花的特征用下面5种属性描述:

扩展:
在鸢尾花中花数据集中,包含150个样本和4个特征,因此将其记作150×4维的矩阵, ,其中R表示向量空间,这里表示150行4维的向量,记作:
,其中R表示向量空间,这里表示150行4维的向量,记作:

一般使用上标(i)来指代第i个训练样本,使用小标(j)来指代训练数据集中第j维特征。一般小写字母代表向量,大写字母代表矩阵。
x2^(150) 表示第150个花样本的第2个特征萼片宽度。在上述X的特征矩阵中,每一行表代表一个花朵的样本,可以记为一个四维行向量
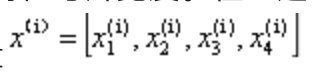
数据中的每一列代表样本的一种特征,可以用一个150维度的列向量表示:

类似地,可以用一个150维度的列向量存储目标变量(类标)
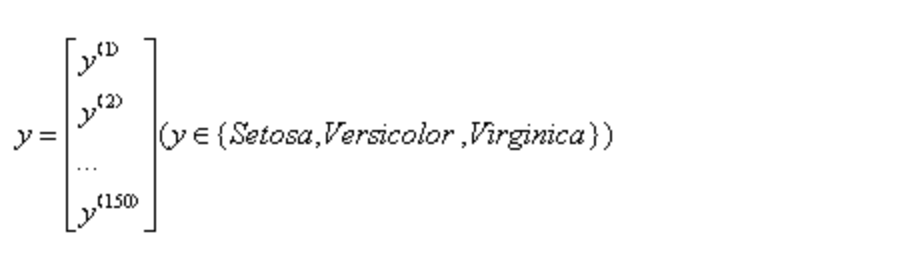
6. 小结
- 基于规则的分类器是使用一组 “if…else…” 规则来对样本进行分类的技术
- 基于模型的学习是从数据集中学习知识来获取模型,通过模型来对样本进行分类的技术
- 机器学习的数据集:样本,特征,目标,训练集,测试集