1. 欠拟合
下图中,蓝色点是初始数据点, 用来训练模型。绿色的线用来表示最佳模型, 红色的线表示当前的模型
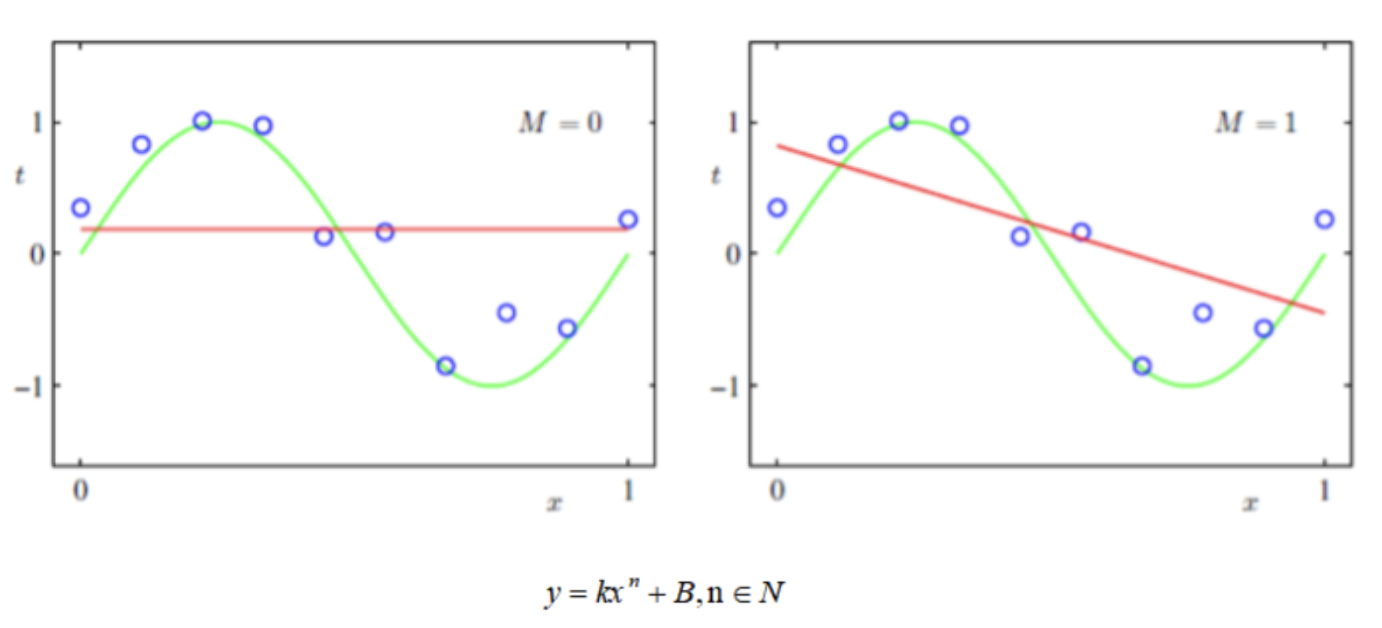
上面两张图中,红色直线代表的模型都属于欠拟合的情况:
- 模型在训练集上表现的效果差,没有充分利用数据
- 预测准确率很低,拟合结果严重不符合预期
产生的原因 :模型过于简单
出现的场景:欠拟合一般出现在机器学习模型刚刚训练的时候,也就是说一开始我们的模型往往是欠拟合也正是因为如此才有了优化的空间,我们通过不断优化调整算法来使得模型的表达能力更强。
解决办法:
- 添加其他特征项:因为特征项不够而导致欠拟合,可以添加其他特征项来很好的解决。
- 添加多项式特征,我们可以在线性模型中通过添加二次或三次项使得模型的泛化能力更强。
- 减少正则化参数,正则化的目的是用来防止过拟合的,但是现在模型出现了欠拟合,需要减少正则化参数。
2. 过拟合
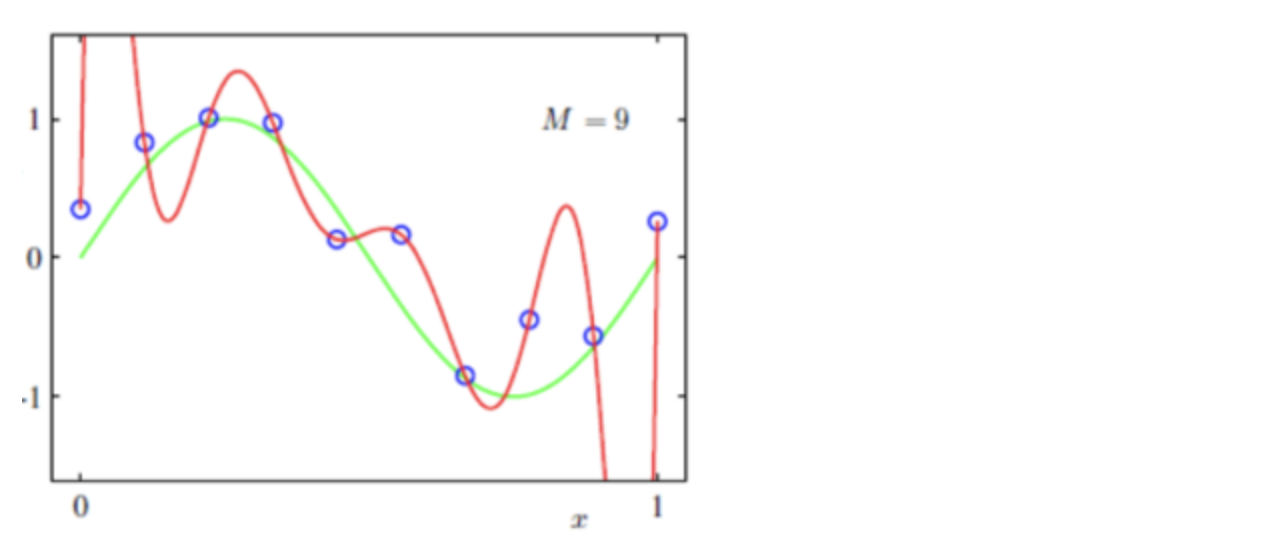
上图是模型过拟合的情况:即模型在训练集上表现的很好,但是在测试集上效果却很差。也就是说,在已知的数据集合中非常好,再添加一些新数据进来效果就会差很多。
产生的原因: 可能是模型太过于复杂、数据不纯、训练数据太少等造成。
出现的场景: 当模型优化到一定程度,就会出现过拟合的情况。
解决办法:
- 重新清洗数据:导致过拟合一个原因可能是数据不纯导致的
- 增大训练的数据量:导致过拟合的另一个原因是训练数据量太小,训练数据占总数据比例太低。
- 采用正则化方法对参数施加惩罚:导致过拟合的原因可能是模型太过于复杂,我们可以对比较重要的特征增加其权重,而不重要的特征降低其权重的方法。常用的有L1正则和L2正则
- 采用dropout方法,即采用随机采样的方法训练模型,常用于神经网络算法中。
注意:模型的过拟合是无法彻底避免的,我们能做的只是缓解,或者说减小其风险,因为机器学习面临的是NP难问题(这列问题不存在有效精确解,必须寻求这类问题的有效近似算法求解),因此过拟合是不可避免的。在实际的任务中往往通过多种算法的选择,甚至对同一个算法,当使用不同参数配置时,也会产生不同的模型。那么,我们也就面临究竟选择哪一种算法,使用哪一种参数配置?这就是我们在机器学习中的“模型选择(model select)”问题,理想的解决方案当然是对候选模型的泛化误差进行评估,然后选择泛化误差最小的那个模型。我们更详细的模型选择会有专门的专题讲到,如具体的评估方法(交叉验证)、性能度量准则、偏差和方差折中等。
3. 奥卡姆剃刀原则
奥卡姆剃刀原则是模型选择的基本而且重要的原则。 模型是越复杂,出现过拟合的几率就越高,因此,我们更喜欢采用较为简单的模型。这种策略与应用就是一直说的奥卡姆剃刀(Occam’s razor)或节俭原则(principe of parsimony)一致。
奥卡姆剃刀:给定两个具有相同泛化误差的模型,较简单的模型比较复杂的模型更可取。
4. 泛化能力
下图是泛化能力较好的图示,M=3表示3次多项式
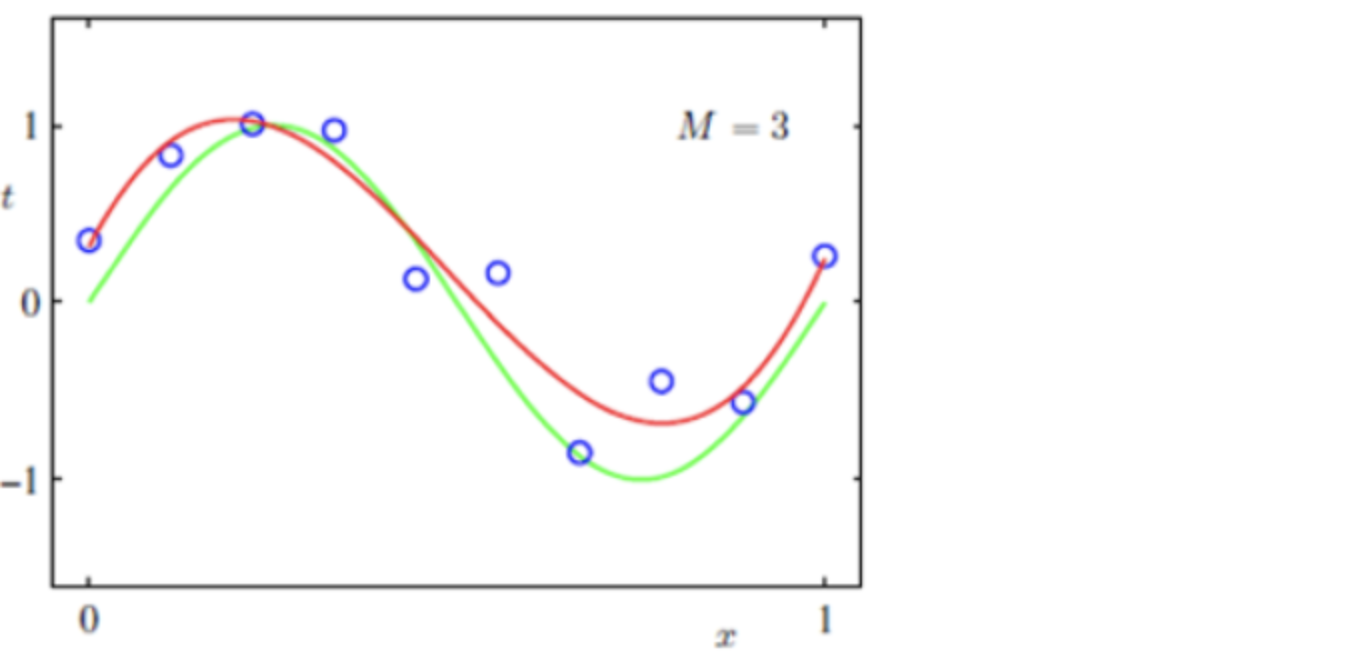
机器学习的目标是使学得的模型能很好地适用于“新样本”,而不是仅仅在训练样本上工作的很好;即便对聚类这样的无监督学习任务,我们也希望学得的簇划分能适用于没在训练集中出现的样本。
学得模型适用于新样本的能力,称为“泛化”(generalization)能力。具有强泛化能力的模型能很好地适用于整个样本空间。(现实任务中的样本空间的规模通常很大,如20 个属性,每个属性有10个可能取值,则样本空间的规模是1020)。
泛化的概念 :
模型具有好的泛化能力指的是:模型不但在训练数据集上表现的效果很好,对于新数据的适应能力也有很好的效果。
当我们讨论一个机器学习模型学习能力和泛化能力的好坏时,我们通常使用过拟合和欠拟合的概念,过拟合和欠拟合也是机器学习算法表现差的两大原因。
5. 小结
- 欠拟合指的是模型在训练集效果不佳,在测试集效果也不佳
- 过拟合指的是模型在训练集效果不错,在测试集效果不佳
- 奥卡姆剃刀原则是模型选择的基本而且重要的原则。模型是越复杂,出现过拟合的几率就越高,因此,我们更喜欢采用较为简单的模型
- 模型的泛化能力指的是对未知样本的预测能力