1. 为什么学习KNN算法
KNN是监督学习分类算法,主要解决现实生活中分类问题。
根据目标的不同将监督学习任务分为了分类学习及回归预测问题。
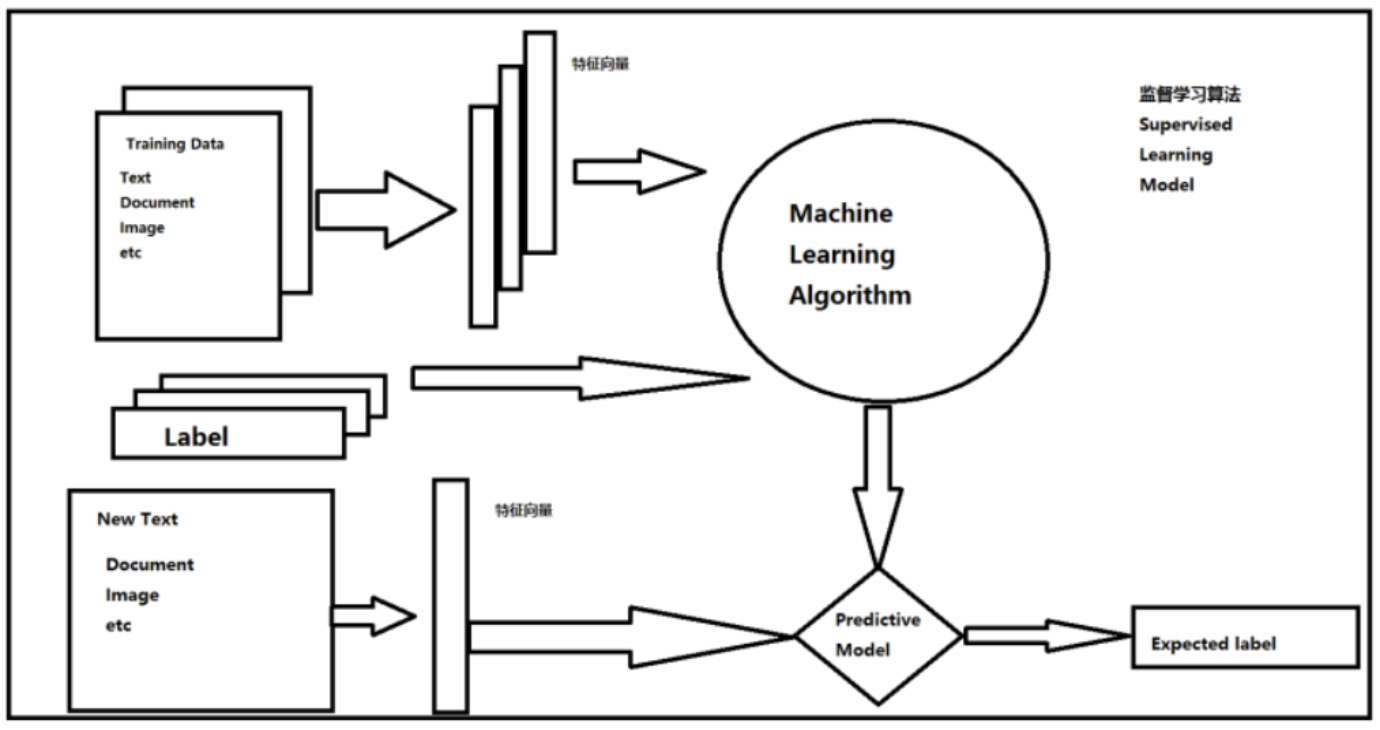
监督学习任务的基本流程和架构:
- 首先准备数据,可以是视频、音频、文本、图片等等
- 抽取所需要的一些列特征,形成特征向量(Feature Vectors)
- 将这些特征向量连同标记(Label)一并送入机器学习算法中,训练出一个预测模型(Predictive Model)。
- 然后,采用同样的特征提取方法作用于新数据,得到用于测试的特征向量。
- 最后,使用预测模型对这些待测的特征向量进行预测并得到结果(Expected Model)。
上述步骤示意如下:
KNN(K-Nearest Neihbor,KNN)K近邻是机器学习算法中理论最简单,最好理解的算法,是一个非常适合入门的算法,拥有如下特性:
- 思想极度简单,应用数学知识少(近乎为零),对于很多不擅长数学的小伙伴十分友好
- 虽然算法简单,但效果也不错
2. KNN 原理
2.1 案例剖析

上图中每一个数据点代表一个肿瘤病历:
- 横轴表示肿瘤大小,纵轴表示发现时间
- 恶性肿瘤用蓝色表示,良性肿瘤用红色表示
疑问:新来了一个病人(下图绿色的点),如何判断新来的病人(即绿色点)是良性肿瘤还是恶性肿瘤?

解决方法:k-近邻算法的做法如下:
(1)取一个值k=3(k值后面介绍,现在可以理解为算法的使用者根据经验取的最优值)
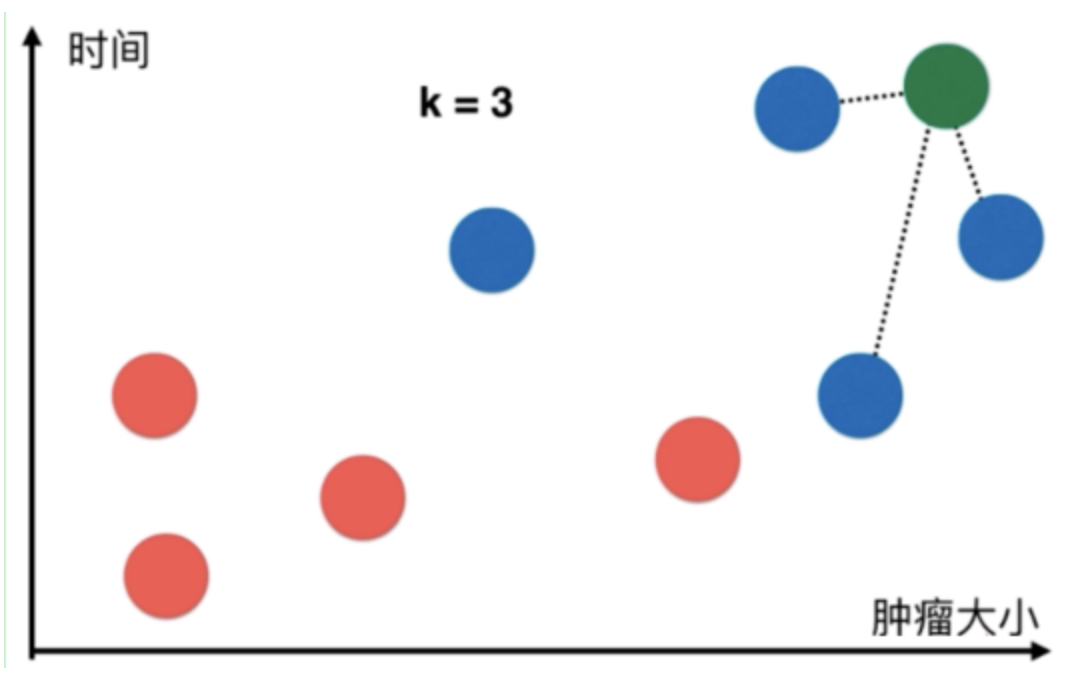
(2)在所有的点中找到距离绿色点最近的三个点
(3)让最近的点所属的类别进行投票
(4)最近的三个点都是蓝色的,所以该病人对应的应该也是蓝色,即恶性肿瘤。
总结:
K-近邻算法属于哪类算法?可以用来解决监督学习中的分类问题
算法的思想:通过K个最近的已知分类的样本来判断未知样本的类别
2.2 算法原理
KNN算法描述
输入:训练数据集
xi为实例的特征向量,yi={C1,c2…Ck}为实例类别。
输出:实例x所属的类别y
步骤:
(1)选择参数K
(2)计算未知实例与所有已知实例的距离(多种方式计算距离)
(3)选择最近K个已知实例
(4)根据少数服从多数的原则进行投票,让未知实例归类为K个最近邻中最多数的类别。
总结:KNN算法没有明显的特征训练过程,它的训练阶段仅仅将样本保存起来,训练开销为0,等到收到测试样本后在进行处理(如K值取值和距离计算)。因此,对应于训练阶段的学习该算法是一种懒惰学习(lazy learning)。

KNN三要素:
- 距离度量
- K值选择
- 分类决策准则
3. 小结
KNN 算法原理简单,不需要训练,属于监督学习算法,常用来解决分类问题
KNN原理:先确定K值, 再计算距离,最后挑选K个最近的邻居进行投票