1. 混淆矩阵
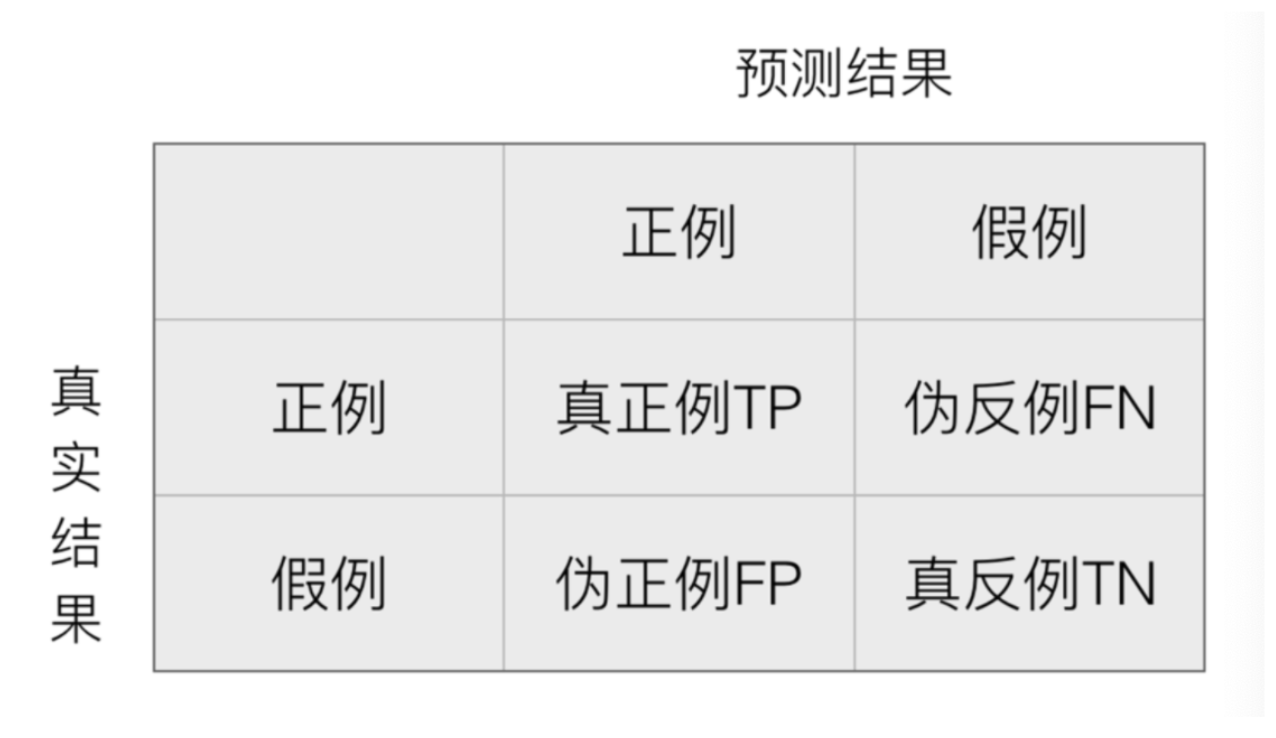
混淆矩阵作用就是看一看在测试集样本集中:
- 真实值是 正例 的样本中,被分类为 正例 的样本数量有多少,这部分样本叫做真正例(TP,True Positive)
- 真实值是 正例 的样本中,被分类为 假例 的样本数量有多少,这部分样本叫做伪反例(FN,False Negative)
- 真实值是 假例 的样本中,被分类为 正例 的样本数量有多少,这部分样本叫做伪正例(FP,False Positive)
- 真实值是 假例 的样本中,被分类为 假例 的样本数量有多少,这部分样本叫做真反例(TN,True Negative)
True Positive :表示样本真实的类别 Positive :表示样本被预测为的类别
例子:
样本集中有 6 个恶性肿瘤样本,4 个良性肿瘤样本,我们假设恶性肿瘤为正例,则:
模型 A: 预测对了 3 个恶性肿瘤样本,4 个良性肿瘤样本
- 真正例 TP 为:3
- 伪反例 FN 为:3
- 伪正例 FP 为:0
- 真反例 TN:4
模型 B: 预测对了 6 个恶性肿瘤样本,1个良性肿瘤样本
- 真正例 TP 为:6
- 伪反例 FN 为:0
- 伪正例 FP 为:3
- 真反例 TN:1
我们会发现:TP+FN+FP+TN = 总样本数量
2. Precision(精准率)
精准率也叫做查准率,指的是对正例样本的预测准确率。比如:我们把恶性肿瘤当做正例样本,则我们就需要知道模型对恶性肿瘤的预测准确率。

例子:
样本集中有 6 个恶性肿瘤样本,4 个良性肿瘤样本,我们假设恶性肿瘤为正例,则:
模型 A: 预测对了 3 个恶性肿瘤样本,4 个良性肿瘤样本
- 真正例 TP 为:3
- 伪反例 FN 为:3
- 假正例 FP 为:0
- 真反例 TN:4
- 精准率:3/(3+0) = 100%
模型 B: 预测对了 6 个恶性肿瘤样本,1个良性肿瘤样本
- 真正例 TP 为:6
- 伪反例 FN 为:0
- 假正例 FP 为:3
- 真反例 TN:1
- 精准率:6/(6+3) = 67%
3. Recall(召回率)
召回率也叫做查全率,指的是预测为真正例样本占所有真实正例样本的比重。例如:我们把恶性肿瘤当做正例样本,则我们想知道模型是否能把所有的恶性肿瘤患者都预测出来。

例子:
样本集中有 6 个恶性肿瘤样本,4 个良性肿瘤样本,我们假设恶性肿瘤为正例,则:
模型 A: 预测对了 3 个恶性肿瘤样本,4 个良性肿瘤样本
- 真正例 TP 为:3
- 伪反例 FN 为:3
- 假正例 FP 为:0
- 真反例 TN:4
- 精准率:3/(3+0) = 100%
- 召回率:3/(3+3)=50%
模型 B: 预测对了 6 个恶性肿瘤样本,1个良性肿瘤样本
- 真正例 TP 为:6
- 伪反例 FN 为:0
- 假正例 FP 为:3
- 真反例 TN:1
- 精准率:6/(6+3) = 67%
- 召回率:6/(6+0)= 100%
4. F1-score
如果我们对模型的精度、召回率都有要求,希望知道模型在这两个评估方向的综合预测能力如何?则可以使用 F1-score 指标。

样本集中有 6 个恶性肿瘤样本,4 个良性肿瘤样本,我们假设恶性肿瘤为正例,则:
模型 A: 预测对了 3 个恶性肿瘤样本,4 个良性肿瘤样本
- 真正例 TP 为:3
- 伪反例 FN 为:3
- 假正例 FP 为:0
- 真反例 TN:4
- 精准率:3/(3+0) = 100%
- 召回率:3/(3+3)=50%
- F1-score:(2*3)/(2*3+3+0)=67%
模型 B: 预测对了 6 个恶性肿瘤样本,1个良性肿瘤样本
- 真正例 TP 为:6
- 伪反例 FN 为:0
- 假正例 FP 为:3
- 真反例 TN:1
- 精准率:6/(6+3) = 67%
- 召回率:6/(6+0)= 100%
- F1-score:(2*6)/(2*6+0+3)=80%
5. ROC曲线和AUC指标
5.1 ROC 曲线
ROC 曲线:我们分别考虑正负样本的情况:
- 正样本中被预测为正样本的概率,即:TPR (True Positive Rate)
- 负样本中被预测为正样本的概率,即:FPR (False Positive Rate)
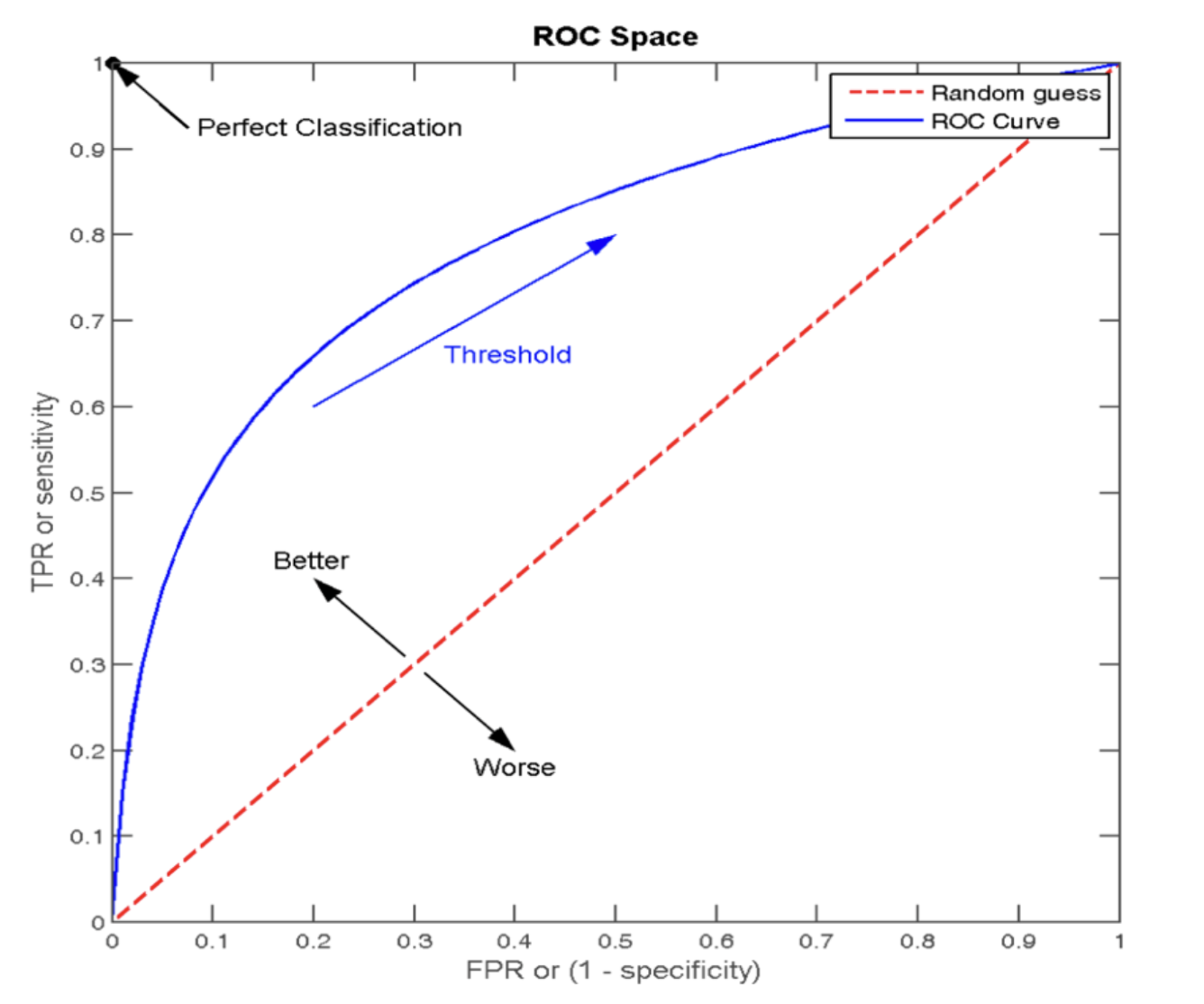
ROC 曲线图像中,4 个特殊点的含义:
- (0, 0) 表示所有的正样本都预测为错误,所有的负样本都预测正确
- (1, 0) 表示所有的正样本都预测错误,所有的负样本都预测错误
- (1, 1) 表示所有的正样本都预测正确,所有的负样本都预测错误
- (0, 1) 表示所有的正样本都预测正确,所有的负样本都预测正确
5.2 绘制 ROC 曲线
假设:在网页某个位置有一个广告图片或者文字,该广告共被展示了 6 次,有 2 次被浏览者点击了。每次点击的概率如下:
| 样本 | 是否被点击 | 预测点击概率 |
|---|---|---|
| 1 | 1 | 0.9 |
| 2 | 0 | 0.7 |
| 3 | 1 | 0.8 |
| 4 | 0 | 0.6 |
| 5 | 0 | 0.5 |
| 6 | 0 | 0.4 |
根据预测点击概率排序之后:
| 样本 | 是否被点击 | 预测点击概率 |
|---|---|---|
| 1 | 1 | 0.9 |
| 3 | 1 | 0.8 |
| 2 | 0 | 0.7 |
| 4 | 0 | 0.6 |
| 5 | 0 | 0.5 |
| 6 | 0 | 0.4 |
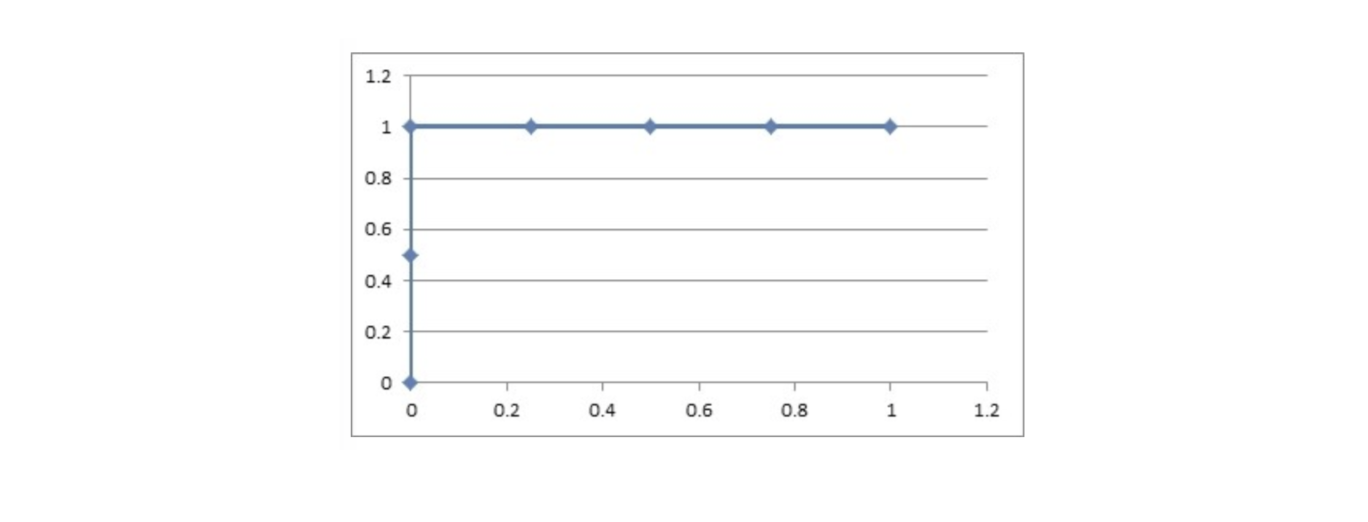
绘制 ROC 曲线:
阈值:0.9
- 原本为正例的 1、3 号的样本中 3 号样本被分类错误,则 TPR = ½ = 0.5
- 原本为负例的 2、4、5、6 号样本没有一个被分为正例,则 FPR = 0
阈值:0.8
- 原本为正例的 1、3 号样本被分类正确,则 TPR = 2/2 = 1
- 原本为负例的 2、4、5、6 号样本没有一个被分为正例,则 FPR = 0
阈值:0.7
- 原本为正例的 1、3 号样本被分类正确,则 TPR = 2/2 = 1
- 原本为负类的 2、4、5、6 号样本中 2 号样本被分类错误,则 FPR = ¼ = 0.25
阈值:0.6
- 原本为正例的 1、3 号样本被分类正确,则 TPR = 2/2 = 1
- 原本为负类的 2、4、5、6 号样本中 2、4 号样本被分类错误,则 FPR = 2/4 = 0.5
阈值:0.5
- 原本为正例的 1、3 号样本被分类正确,则 TPR = 2/2 = 1
- 原本为负类的 2、4、5、6 号样本中 2、4、5 号样本被分类错误,则 FPR = ¾ = 0.75
阈值 0.4
- 原本为正例的 1、3 号样本被分类正确,则 TPR = 2/2 = 1
- 原本为负类的 2、4、5、6 号样本全部被分类错误,则 FPR = 4/4 = 1
(0, 0.5)、(0, 1)、(0.25, 1)、(0.5, 1)、(0.75, 1)、(1, 1)
由 TPR 和 FPR 构成的 ROC 图像为:
5.3 AUC 值
我们发现:
- 我们发现:图像越靠近 (0,1) 点则模型对正负样本的辨别能力就越强
- 我们发现:图像越靠近 (0, 1) 点则 ROC 曲线下面的面积就会越大
- AUC 是 ROC 曲线下面的面积,该值越大,则模型的辨别能力就越强
- AUC 范围在 [0, 1] 之间
- 当 AUC= 1 时,该模型被认为是完美的分类器,但是几乎不存在完美分类器
AUC 值主要评估模型对正例样本、负例样本的辨别能力.
6. API介绍
6.1 分类评估报告api
sklearn.metrics.classification_report(y_true, y_pred, labels=[], target_names=None )
'''
y_true:真实目标值
y_pred:估计器预测目标值
labels:指定类别对应的数字
target_names:目标类别名称
return:每个类别精确率与召回率
'''
6.2 AUC计算API
from sklearn.metrics import roc_auc_score
sklearn.metrics.roc_auc_score(y_true, y_score)
计算ROC曲线面积,即AUC值
y_true:每个样本的真实类别,必须为0(反例),1(正例)标记
y_score:预测得分,可以是正例的估计概率、置信值或者分类器方法的返回值
7. 小结
1、当样本分布不均衡时,使用准确率(accuracy_score)进行模型评估不能反应模型真实效果
2、通过混淆矩阵, 可以计算出精准率, 召回率,F1Score等指标
3、通过ROC曲线可以计算出AUC指标